
티스토리 뷰
지금까지 지도 학습을 통해 데이터를 분류하거나 회귀를 이용하여 수를 예측하는 모델을 배웠다면, 특정 데이터가 도출될 확률을 구하는 건 어떨까?
확률은 숫자니까 회귀로 풀어야 하나? 혹은 "특정" 데이터가 나올 확률이니 분류인가?
k-최근접 이웃 알고리즘과 선형 회귀 알고리즘 모두 어떤 데이터가 나올 확률을 구할 수 있도록 제공한다.
로지스틱 회귀에 대하여 다루기 전에 k-최근접 이웃 알고리즘으로 특정 데이터를 분류할 확률을 먼저 구한 뒤, 그 한계를 알아보자.
예제에서 사용할 데이터는 생선의 종 이름과 무게, 길이, 대각선, 높이, 너비 데이터이다.
우선, k-최근접 이웃 알고리즘을 사용하여 각 특성에 맞는 생선 종류를 예측하는 모델을 만들자.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 데이터 준비
fish = pd.read_csv('https://bit.ly/fish_csv_data')
print(fish.head())
# Species Weight Length Diagonal Height Width
# 0 Bream 242.0 25.4 30.0 11.5200 4.0200
# 1 Bream 290.0 26.3 31.2 12.4800 4.3056
# 2 Bream 340.0 26.5 31.1 12.3778 4.6961
# 3 Bream 363.0 29.0 33.5 12.7300 4.4555
# 4 Bream 430.0 29.0 34.0 12.4440 5.1340
print(pd.unique(fish['Species']))
#['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']
# input 데이터
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
print(fish_input[:5])
# [[242. 25.4 30. 11.52 4.02 ]
# [290. 26.3 31.2 12.48 4.3056]
# [340. 26.5 31.1 12.3778 4.6961]
# [363. 29. 33.5 12.73 4.4555]
# [430. 29. 34. 12.444 5.134 ]]
# target 데이터
fish_target = fish['Species'].to_numpy()
# 훈련, 테스트 데이터 셋 나누기
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
# 데이터 전처리, 스케일 조정
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# k = 3으로 최근접 이웃 알고리즘 모델 생성
kn = KNeighborsClassifier(n_neighbors=3)
# 훈련
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
#0.8907563025210085
print(kn.score(test_scaled, test_target))
#0.85
# Target의 종류
print(kn.classes_)
#['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
# 맨 앞 5개 데이터의 예측값
print(kn.predict(test_scaled[:5]))
#['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']
# 실제 Target 데이터
print(test_target[:5])
#['Perch' 'Smelt' 'Pike' 'Whitefish' 'Perch']k = 3으로 설정하고 k-최근접 이웃 모델을 돌려, input 데이터에 따른 예측 분류를 확인해보면, 5개 데이터 중 4개를 맞춘 걸 확인할 수 있다.
k-최근접 이웃 모델에서 확률은 최근접 이웃이 존재하는 확률 분포를 확인하면 되는데, 이는 아래와 같이 predict_proba 함수를 사용하면 된다.
# kn.classes_ 로 얻은 순서대로 결과가 도출될 확률
# 최근접 이웃이 존재하는 확률 분포
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
# [[0. 0. 1. 0. 0. 0. 0. ]
# [0. 0. 0. 0. 0. 1. 0. ]
# [0. 0. 0. 1. 0. 0. 0. ]
# [0. 0. 0.6667 0. 0.3333 0. 0. ]
# [0. 0. 0.6667 0. 0.3333 0. 0. ]]
# 4번째 타깃의 최근접 이웃 확인
distandces, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
#[['Roach' 'Perch' 'Perch']]['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']의 순서대로 최근접 이웃이 존재할 확률을 나타낸 것이다. 예를 들어, 첫번째 샘플은 3개의 이웃 모두 perch기 때문에 예측값도 Perch로 예측한다.
k-최근접 이웃 모델을 사용하여 각 분류를 예측할 확률을 알아봤는데, 이렇게 되면 k가 3이기 때문에 각 이웃이 존재할 확률은 0, 1/3, 2/3, 1이 전부이며, 이는 굉장히 디테일이 떨어지는, 만족스럽지 않은 결과라고 할 수 있다.
그럼 이제, 확률 분포를 구하는 좀 더 확실한 방법인 로지스틱 회귀에 대하여 확인해보자.
로지스틱 회귀
로지스틱 회귀는 회귀이지만, 분류 모델이다. 이 알고리즘은 선형 회귀와 동일하게 선형 방정식을 학습하는데, 각 특성에 가중치를 곱하고, 절편을 더하는 전형적인 선형 방정식이다.
방정식을 예를 들면 다음과 같다.
z = a*weight - b*length - c*diagonal - d*height - e*width - f이때, z의 값은 어떤 값도 가능하다. 로지스틱 회귀 모델에서는 이 z의 값을 시그모이드 함수(sigmoid, 혹은 로지스틱 함수)를 사용하여 z가 아주 큰 음수일 때는 0, 아주 큰 양수 일때는 1이 되는 형태로 치환하여 확률을 구해 분류에 사용한다.
시그모이드 함수의 수식과 그래프는 아래와 같다.
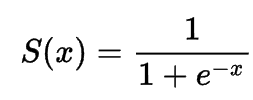

이로써, z의 값이 어떤 값이 나오더라도 0% ~ 100% 까지의 확률로 확인하는 것이 가능해진다.
이 로지스틱 회귀를 이용하여 전체 데이터의 분류 확률을 확인하기 전에, 간단하게 Bream(도미), Smelt(빙어) 두 종류의 생선만 추려 이진 분류를 먼저 실습해보자.
이진 분류의 경우, 시그모이드 함수의 출력이 0.5보다 크면 양성 클래스, 0.5보다 작으면 음성 클래스로 판단한다.
바로 코드와 함께 로지스틱 회귀 모델을 확인해보자.
from sklearn.linear_model import LogisticRegression
# 로지스틱 회귀를 사용하기 위해 훈련 세트에서 Bream(도미), Smelt(빙어)의 행만 골라낸다.
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
print(train_bream_smelt)
# 로지스틱 회귀 모델
lr = LogisticRegression()
# 데이터 학습
lr.fit(train_bream_smelt, target_bream_smelt)
# 분류
print(lr.predict(train_bream_smelt[:5]))
#['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
# 첫번째 열이 음성 클래스에 대한 확률이고, 두번째 열이 양성 클래스에 의한 확률이다.
print(lr.predict_proba(train_bream_smelt[:5]))
# [[0.99759855 0.00240145]
# [0.02735183 0.97264817]
# [0.99486072 0.00513928]
# [0.98584202 0.01415798]
# [0.99767269 0.00232731]]
print(lr.classes_)
# ['Bream' 'Smelt']
# 즉, smelt가 양성 클래스이다.
# 이제 로지스틱 회귀가 학습한 계수를 확인해보자
print(lr.coef_, lr.intercept_)
#[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]
# 즉, z = -0.404*weight - 0.576*length - 0.663*diagonal - 1.013*height - 0.732*width - 2.161
# 샘플 5개의 z 값을 확인해보면,
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
#[-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
# 확률을 구하고 싶기 때문에 시그모어드 함수를 통과시켜 0 ~ 100 사이의 값으로 치환하자.
from scipy.special import expit
print(expit(decisions))
#[0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
# 양성 클래스가 나올 확률을 좀 더 정확하게 얻어낼 수 있다.이진 분류는 타깃 클래스를 양성, 음성 클래스로 나누어 확률을 구하기 때문에 맨 밑에 줄에서 시그모이드 함수를 통과시킨 z의 값을 확인해보면, 양성 클래스인 smelt가 나올 확률이 97%정도가 되어 얻어진 분류 샘플이
['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']인 걸 납득할 수 있다. 거기다 확률도 꽤나 디테일하게 나온다.
이제 데이터를 모두 사용하여 다중 분류를 진행해보고, 각 데이터가 도출될 확률도 확인해보자.
### 이제 이진 분류가 아닌 다중 분류를 수행해보자 ###
# C는 LogisticRegression에서 규제를 제어하는 매개변수이며, 작을수록 규제가 커진다. default 값은 1이다.
lr = LogisticRegression(C = 20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
#0.9327731092436975
print(lr.score(test_scaled, test_target))
#0.925
print(lr.predict(test_scaled[:5]))
#['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3))
# [[0. 0.014 0.841 0. 0.136 0.007 0.003]
# [0. 0.003 0.044 0. 0.007 0.946 0. ]
# [0. 0. 0.034 0.935 0.015 0.016 0. ]
# [0.011 0.034 0.306 0.007 0.567 0. 0.076]
# [0. 0. 0.904 0.002 0.089 0.002 0.001]]타깃 클래스의 순서가
['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']이므로, 가장 높은 확률을 가지는 데이터를 예측 값으로 분류했다는 걸 알 수 있다.
이제, 다중 분류의 경우 선형 방정식이 어떤 형태인 지 확인해보면
print(lr.coef_.shape, lr.intercept_.shape)
#(7, 5) (7,)계수 배열의 열은 5개인데, 그 행과 intercept의 행도 7개인 것을 알 수 있다.
타깃 데이터의 종류도 7종이니, 각 클래스마다 z를 계산한다는 뜻이다. 당연히 가장 높은 z 값을 출력하는 클래스가 예측 클래스가 되는 것이다.
그럼 그 확률은 어떻게 계산이 되는 걸까?
이진 분류에서는 시그모이드 함수를 사용하여 z를 0과 1 사이의 값으로 변환했다면, 다중 분류는 이와 달리 소프트맥스 함수를 사용하여 7개의 z 값을 확률로 변환한다.
시그모이드 함수는 하나의 선형 방정식의 출력값을 0 ~ 1로 압축한다면, 소프트맥스 함수는 여러 개의 선형 방정식의 출력값을 0 ~ 1 사이로 압축하고 전체 합이 1이 되도록 만든다.
이를 위해 지수 함수를 사용하기 때문에 정규화된 지수 함수라고도 부른다.
소프트맥스 함수의 수식은 아래와 같다.
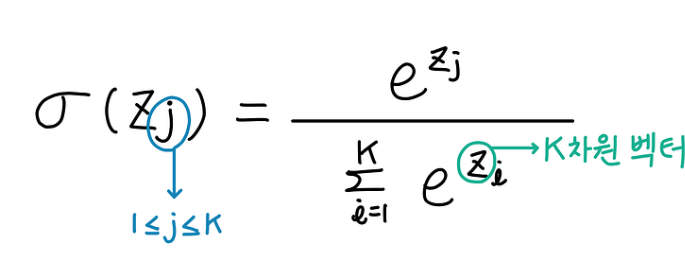
즉, 각 클래스의 z 값을 모두 지수함수로 변환한 뒤에 분모는 각 지수함수를 모두 더한 값으로 고정하고 분자는 하나의 지수함수로 두는 것이다.
이렇게 하면 각 클래스의 결과값을 모두 더하면 1이 나오게 된다.
각 클래스의 z값을 소프트맥스 함수를 사용하여 확률로 바꾸는 걸 아래 코드에서 확인할 수 있다.
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals = 2))
# [[ -6.5 1.03 5.16 -2.73 3.34 0.33 -0.63]
# [-10.86 1.93 4.77 -2.4 2.98 7.84 -4.26]
# [ -4.34 -6.23 3.17 6.49 2.36 2.42 -3.87]
# [ -0.68 0.45 2.65 -1.19 3.26 -5.75 1.26]
# [ -6.4 -1.99 5.82 -0.11 3.5 -0.11 -0.71]]위에서는 각 클래스의 z값을 확인하고, scipy에서 제공하는 소프트맥스 함수를 사용하여 각 클래스에 대한 확률을 구했다.
axis는 소프트맥스를 계산할 축을 지정한다.
아래에서는 axis는 1로 지정하여 각 행, 즉 각 샘플에 대하여 소프트맥스를 계산했다. 매개변수를 지정하지 않으면, 배열 전체에 대하여 소프트맥스를 계산한다.
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
# [[0. 0.014 0.841 0. 0.136 0.007 0.003]
# [0. 0.003 0.044 0. 0.007 0.946 0. ]
# [0. 0. 0.034 0.935 0.015 0.016 0. ]
# [0.011 0.034 0.306 0.007 0.567 0. 0.076]
# [0. 0. 0.904 0.002 0.089 0.002 0.001]]아까 로지스틱 회귀를 사용한 다중 분류에서 얻은 확률값과 동일한 값을 얻었다!
이로써 로지스틱 회귀를 사용하여 선형 방정식을 사용한 분류 알고리즘을 알아봤으며, 시그모이드 함수와 소프트맥스 함수가 어떤 것인지 학습했다.
끝!
'[Python] > Machine learning' 카테고리의 다른 글
| [ML] 지도 학습 6: 결정 트리 (0) | 2023.02.26 |
|---|---|
| [ML] 지도 학습 5: 확률적 경사 하강법 (0) | 2023.02.24 |
| [ML] 지도 학습 3: 다중 회귀(특성 공학과 규제) (0) | 2023.02.21 |
| [ML] 지도 학습 2: 선형 회귀 (0) | 2023.02.20 |
| [ML] 지도 학습 1: k-nearest neighbors 알고리즘 (0) | 2023.02.20 |




- 파니노구스토
- 인천 구월동 이탈리안 맛집
- Promise
- 맛집
- react-native
- react
- await
- redux
- 인천 구월동 맛집
- 이탈리안 레스토랑
- 정보보안기사 #실기 #정리
- redux-thunk
- AsyncStorage
- Async
- javascript
- Total
- Today
- Yesterday