
티스토리 뷰
우선 파이썬3 의 표준 타입 계층 구조는 다음과 같다.
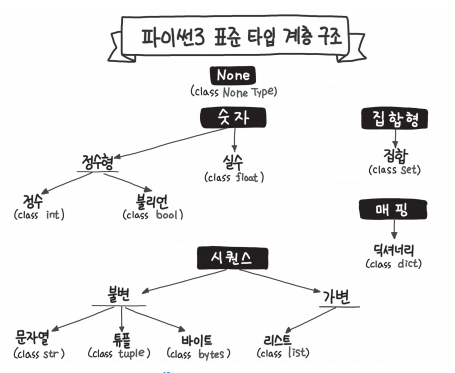
숫자와 문자 자료형은 자바의 자료형과 거의 비슷하니, 생략하고 본 포스팅에서는 코딩 테스트에도 실제로 굉장히 유용하게 쓰이는 파이썬의 대표 자료구조인 리스트, 튜플, 딕셔너리 이렇게 3가지 자료구조를 정리하려 한다.
-
리스트(List)
리스트는 인덱스를 가지고, 동일하거나 혹은 동일하지 않는 형태의 자료들이 차례차례 들어있는 배열이다.
즉, 데이터를 "순서대로" 저장하고 활용하기 위한 자료구조라고 볼 수있다.
1) 생성
리스트는 다음과 같은 방법으로 생성할 수 있다.
first_list = [1,2,3,4,5]
print(first_list)
>>> [1, 2, 3, 4, 5]
2) 리스트 인덱싱
리스트는 인덱스 값을 통해 가리키는 값에 접근하여 활용할 수 있다. 인덱스는 다른 프로그래밍 언어와 같이 0 부터 시작한다.
first_list = [1,2,3,4,5]
for i in range(0, 5, 1):
print(first_list[i])
print(first_list[-1]) ##리스트의 마지막 인자>>>
1
2
3
4
5
5
3) 리스트 슬라이싱
리스트의 부분을 통째로 사용하기 위한 슬라이싱 방법이다.
first_list = [1,2,3,4,5]
print(first_list[0:2])위 코드는 리스트의 0번 인덱스부터 2번 인덱스까지의 부분을 출력하는 코드인데, 머리 속으로는 [1,2,3]이 출력되어야 할 거 같지만, 실제로 출력되는 값은 [1,2]가 출력된다.
이것이 바로 리스트 슬라이싱의 주의점이다.
인덱스는 리스트에 들어있는 값이 있는 바로 그 위치에 지정되지 않는다는 것!
그림으로 보면 리스트 인덱싱은 다음과 같이 지정된다.

즉, 위 그림으로 보면 2번 인덱스 까지 출력하는 것은 [1,2]를 출력하는 것이다.
그렇기 때문에 중간 지점부터 끝 인덱스까지 출력하려면
first_list[2:4] 가 아닌, first_list[2:5] 라고 작성해야 정상적인 출력 값을 얻을 수 있다.
또한 아래 코드와 같이 슬라이싱의 시작, 끝 값을 생략할 수도 있다.
first_list = [1,2,3,4,5]
print(first_list[2:]) 2번부터 끝까지
print(first_list[:3]) 0번부터 3까지
>>>
[3, 4, 5]
[1, 2, 3]
4) 리스트에 데이터 삽입
- append: 리스트의 마지막 부분에 차곡차곡 데이터를 채워넣는다.
- insert: 지정한 인덱스에 데이터를 끼워넣는다.
first_list = [1,2,3,4,5]
first_list.append(9999)
print(first_list)
first_list.insert(5, 8888)
print(first_list)
>>>
[1, 2, 3, 4, 5, 9999]
[1, 2, 3, 4, 5, 8888, 9999]
5) 리스트의 데이터 삭제
삭제 연산은 del 또는 remove 함수를 사용한다.
first_list = [1,2,3,4,5]
first_list.append(9999)
print(first_list)
first_list.insert(5, 8888)
print(first_list)
del first_list[3]
print(first_list)
first_list.remove(-1)
print(first_list)>>>
[1, 2, 3, 4, 5, 9999]
[1, 2, 3, 4, 5, 8888, 9999]
[1, 2, 3, 5, 8888, 9999]
-
튜플(tuple)
리스트는 '[ ]'를 사용하는 반면 튜플은 '( )'를 사용하며, 리스트는 리스트 내의 원소를 변경할 수 있지만 튜플은 변경할 수 없다. 이 점을 제외하고는 리스트와 딱히 다를 게 없지만, 튜플은 리스트보다 속도가 빠르다는 장점이 있다.
때문에 정보를 변경할 필요가 없는 경우에는 튜플을 사용하는 것이 더 좋다.
간단한 예제만 하나 보고 넘어가자.
t = ('Samsung', 'LG', 'SK')
print(t)
print(len(t))
print(t[1])>>>
('Samsung', 'LG', 'SK')
3
LG
튜플이 ( ) 기호를 사용한다고, 인덱스를 뽑을 때도 ( ) 를 사용하면 안된다. 인덱싱은 반드시 [ ] 기호를 사용한다.
슬라이싱도 리스트와 마찬가지로 [ ] 기호를 사용한다.
-
딕셔너리
딕셔너리는 말 그대로 "사전"이라는 의미를 가진 자료 구조이다. 파이썬에서 유일하게 가지고 있는 map 형태의 자료구조로, key와 value 쌍을 이용하여 자료를 저장한다.
딕셔너리는 { } 기호로 생성한다.
first_dict = {1:"holy", 2:"moly"}
print(first_dict)
>>>
{1: 'holy', 2: 'moly'}
마찬가지로 key 값을 이용하여 value값을 찾아낼 수 있다.
first_dict = {1:"holy", 2:"moly"}
print(first_dict[1])
>>>holy
HashMap 과 동일하게 순서가 없고, key와 value로 값을 저장하기 때문에 len() 은 사용 가능하지만, 인덱싱을 따로 지원하지는 않는다.
- 데이터의 삽입과 삭제
리스트와 마찬가지로 딕셔너리 또한 데이터의 삽입과 삭제가 가능하다.
1) 삽입
first_dict = {1:"holy", 2:"moly"}
print(first_dict)
first_dict[3] = "Ya!!!"
print(first_dict)
>>>
{1: 'holy', 2: 'moly'}
{1: 'holy', 2: 'moly', 3: 'Ya!!!'}
2) 삭제
first_dict = {1:"holy", 2:"moly"}
print(first_dict)
first_dict[3] = "Ya!!!"
print(first_dict)
del first_dict[2]
print(first_dict)
>>>
{1: 'holy', 2: 'moly'}
{1: 'holy', 2: 'moly', 3: 'Ya!!!'}
{1: 'holy', 3: 'Ya!!!'}
또한 아래 코드와 같이 key, value 값들을 확인할 수도 있다.
first_dict = {1:"holy", 2:"moly"}
first_dict[3] = "Ya!!!"
print(list(first_dict.keys()))
print(list(first_dict.values()))
>>>
[1, 3]
['holy', 'Ya!!!']
끝!!!
'[Python]' 카테고리의 다른 글
| [Python] Thread & Timer (0) | 2021.05.04 |
|---|---|
| [Python] 정규표현식(regex) (0) | 2021.05.03 |
| [Python] 예외 처리 (0) | 2021.04.17 |
| [Python] 접근 제한자 (0) | 2021.04.17 |
| [Python] 기본 문법 정리 (0) | 2021.04.16 |


- redux-thunk
- AsyncStorage
- Promise
- 파니노구스토
- await
- 정보보안기사 #실기 #정리
- 이탈리안 레스토랑
- 맛집
- react-native
- 인천 구월동 맛집
- react
- redux
- Async
- 인천 구월동 이탈리안 맛집
- javascript
- Total
- Today
- Yesterday