
티스토리 뷰
문자열 조작에 있어서 아주 편리하게 사용할 수 있는 정규표현식에 대하여 알아보자.
정규표현식은 반드시 typing의 re 모듈을 import 해야 사용할 수 있다.
1. 메타 문자
메타 문자는 보통 어떤 문자열 안에 와일드 문자로써 사용되는 경우가 많기 때문에 백슬레시와 같은 문자를 사용할 때는 반드시 백슬레시를 한번 더 사용하여 이스케이프 처리를 해야한다.
1) [ ]
[ ] 내부 문자열과 매치되는 것
import re
test = re.compile('[abc]')
print(test.findall('a abc ccc aaa bbb'))>>>
['a', 'a', 'b', 'c', 'c', 'c', 'c', 'a', 'a', 'a', 'b', 'b', 'b']
또한 [] 를 이용하여 특정 패턴을 모두 표기할 수 있다.
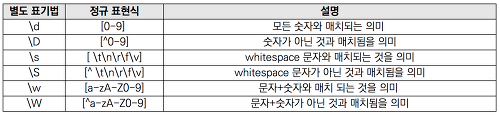
2) . (dot)
줄바꿈 문자인 \n을 제외한 모든 하나의 문자와 매치되는 것을 의미한다.
import re
test = re.compile('a.b')
print(test.findall('aasdfb asb a2b sdfva ab ba'))
test = re.compile('a...b')
print(test.findall('aasdfb asb a2b sdfva ab ba'))>>>
['asb', 'a2b']
['asdfb']
3) *
반복을 나타내는 문자로써, 해당 문자 앞의 글자가 0번 이상 반복되는 모든 문자열과 매치
4) +
+는 *과 같은 반복을 나타내는 메타문자이다. *는 다르게 앞의 글자가 0번을 제외한, 1번이상 반복되는 모든 문자열과 매치된다.
5) {m, n}
m,n}또한 반복을 나타내는 메타문자이다. 위와는 다르게 반복횟수를 m과 n으로 정할 수 있습니다. 즉, 앞의 문자가 m번 이상 n번이하 반복되는 모든 문자열과 매치된다.
6) ?
? 는 앞의 문자가 0~1번 반복되는 모든 문자열과 매치된다.
import re
test = re.compile('go*gle')
print(test.findall('ggle gogle google goooogle goooooogle'))
test = re.compile('go+gle')
print(test.findall('ggle gogle google goooogle goooooogle'))
test = re.compile('go{1, 4}gle')
print(test.findall('ggle gogle google goooogle goooooogle'))
test = re.compile('go?gle')
print(test.findall('ggle gogle google goooogle goooooogle'))>>>
['ggle', 'gogle', 'google', 'goooogle', 'goooooogle']
['gogle', 'google', 'goooogle', 'goooooogle']
[]
['ggle', 'gogle']
7) |
or로 사용된다.
import re
test = re.compile('bok|book')
print(test.findall('book is'))
test = re.compile('bok|book')
print(test.findall('The bok is')) >>>
['book']
['bok']
8) ^
문자열의 맨 처음을 의미하는 메타 문자이며, 문자열 내부에서 not의 의미로 사용되기도 한다.
import re
test = re.compile('^book')
print(test.findall('book is'))
test = re.compile('^book')
print(test.findall('The book is'))
>>>
['book']
[]
9) $
^와 반대로 문자열의 맨 마지막을 의미하는 메타문자이다.
import re
test = re.compile('book$')
print(test.findall('this is a book'))
test = re.compile('book$')
print(test.findall('this is a bok'))>>>
['book']
[]
10) \A
라인별이 아닌 문자열 전체에서의 맨 처음을 나타낸다. (re.MULTILINE)을 사용하지 않았을 때는 ^와 동일하다.
11) \Z
라인별이 아닌 문자열 전체에서의 맨 뒤를 나타낸다. (re.MULTILINE)을 사용하지 않았을 때는 &와 동일하다.
12) \b
공백을 의미하며 단어 구분자로 사용한다.
13) \B
공백을 포함하지 않은 문자열을 찾는데 사용한다.
2. 함수
1) match
re.match 함수는 문자열의 처음부터 시작하여 패턴이 일치하는 것이 있는 지를 확인하는 데 사용한다.
import re
matchObj = re.match('a', 'a')
print(matchObj)
print(re.match('a', 'aba'))
print(re.match('a', 'bbb'))
print(re.match('a', 'baa'))>>>
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='a'>
None
None
2) search
re.search 함수는 re.match와 비슷하지만, 반드시 문자열의 처음부터 일치해야 하는 것은 아니다.
matchObj = re.search('a', 'a')
print(matchObj)
print(re.search('a', 'aba'))
print(re.search('a', 'bbb'))
print(re.search('a', 'baa'))>>>
<re.Match object; span=(0, 1), match='a'>
<re.Match object; span=(0, 1), match='a'>
None
<re.Match object; span=(1, 2), match='a'>
3) findall
re.findall 은 문자열 중 패턴과 일치하는 모든 부분을 찾는다.
import re
matchObj = re.findall('a', 'a')
print(matchObj)
print(re.findall('a', 'aba'))
print(re.findall('a', 'bbb'))
print(re.findall('a', 'baa'))
print(re.findall('aaa', 'aaaa'))>>>
['a']
['a', 'a']
[]
['a', 'a']
['aaa']이때, 반환된 리스트는 서로 겹치지 않는다.
4) finditer
re.findall 은 위와 같이 리스트 형태로 반환하지만, finditer는 다른 함수들과 마찬가지로 match Object 형식으로 반환한다.
import re
matchObj_iter = re.finditer('a', 'baa')
print(matchObj_iter)
for matchObj in matchObj_iter:
print(matchObj)
>>>
<callable_iterator object at 0x000002C5E1043CC8>
<re.Match object; span=(1, 2), match='a'>
<re.Match object; span=(2, 3), match='a'>
5) sub
re.sub 는 문자열을 치환하기 위해 사용한다.
re.sub(정규표현식, 대상 문자열, 치환 문자")
import re
text = "I like apble And abple"
text_mod = re.sub('apble|abple',"apple",text)
print (text_mod)>>>
I like apple And apple
3. match Object
대부분의 regex 함수들은 matchObject 형태로 값을 반환하기 때문에 match 객체의 메서드를 따로 사용하여 반환된 값을 조작할 수도 있다.
1) group(): 매치된 문자열을 돌려준다.
2) start(): 매치된 문자열의 시작 위치를 돌려준다.
3) end(): 매치된 문자열의 끝 위치를 돌려준다.
4) span(): 매치된 문자열의 (시작, 끝)에 해당하는 튜플을 돌려준다.
import re
test = re.compile('book')
m = test.search('book')
print(m.group())
print(m.start())
print(m.end())
print(m.span())
>>>
book
0
4
(0, 4)
'[Python]' 카테고리의 다른 글
| [Python] 최대, 최소값을 구하기 위한 초기값 선언 (0) | 2021.05.10 |
|---|---|
| [Python] Thread & Timer (0) | 2021.05.04 |
| [Python] 예외 처리 (0) | 2021.04.17 |
| [Python] 접근 제한자 (0) | 2021.04.17 |
| [Python] 파이썬의 기본 자료 구조 (0) | 2021.04.16 |

- 맛집
- Async
- 인천 구월동 맛집
- react-native
- react
- Promise
- redux
- 인천 구월동 이탈리안 맛집
- AsyncStorage
- 파니노구스토
- await
- 이탈리안 레스토랑
- 정보보안기사 #실기 #정리
- javascript
- redux-thunk
- Total
- Today
- Yesterday