
티스토리 뷰
앞서 머신러닝의 지도 학습, 비지도 학습을 대표하는 각각의 알고리즘을 예제와 함께 실습하며 머신 러닝을 조금 핥아봤다.
완벽하지는 않지만, 이제 어느 정도 친해진 거 같으니 딥러닝을 다뤄보자.
이번 글에서는 28 x 28 픽셀로 이뤄진 사진 데이터 샘플과 텐서플로를 가지고 직접 인공 신경망을 만들어보며, 딥러닝이 무엇인지, 텐서플로가 뭔지 알아보려고 한다.
바로 시작해보자.
우선 데이터 셋은 패션 MNIST 데이터 셋을 사용하는데, 이는 10가지의 패션 아이템 사진 샘플이 각 6000장 씩 들어있는 데이터 셋이다.
우선, 아래와 같이 텐서플로의 케라스를 임포트하고 데이터를 로드한다.
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
# 훈련 데이터와 테스트 데이터를 나누자.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
# 훈련 데이터의 크기 확인
print(train_input.shape, train_target.shape)
# 테스트 데이터의 크기 확인
print(test_input.shape, test_target.shape)
# 훈련 데이터에서 10개의 샘플만 이미지로 확인해보자.
fig, axs = plt.subplots(1, 10, figsize=(10, 10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
# 타깃 레이블 확인
print([train_target[i] for i in range(10)])
# [9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
# 0: 티셔츠, 1: 바지, 2: 스웨터, 3: 드레스, 4: 코트, 5: 샌달, 6:셔츠, 7: 스니커즈, 8: 가방, 9: 앵클 부츠
print(np.unique(train_target, return_counts=True))
#(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000], dtype=int64))
# 각 레이블마다 6000개의 샘플이 있다.

딥러닝의 인공 신경망을 들어가기 전에, 일반적인 머신러닝 모델로 위 데이터를 분류하는 방법을 생각해보자.
샘플이 60000개나 되기 때문에 전체 데이터를 한꺼번에 훈련하는 모델보다는 샘플을 하나씩 꺼내서 모델을 훈련하는 방식이 더 효율적일 거 같다.
이런 상황에 제일 최적인 확률적 경사 하강법 모델을 사용하여 데이터를 분류해보자.
# 확률적 경사 하강법을 훈련시키고 교차 검증 점수를 확인해보자.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=20, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
# 0.8192833333333333 (when max_iter=5)
# 0.8305833333333335 (when max_iter=9)
# 0.84365 (when max_iter=20)흠... max_iter 매개변수의 값을 증가시켜면 모델의 성능이 향상되지만, 만족할만한 수준은 아니다.
위 경사 하강법에서 loss 매개변수를 log로 두며 로지스틱 회귀 공식을 사용했는데, 로지스틱 회귀는 각 특성을 모두 방정식에 집어넣고 각 타깃 클래스마다 다른 절편을 사용하여 결과값인 z를 얻어내는 방식이다.
잘 생각나지 않는다면 여기에서 복습하자.
즉, 사진 데이터의 경우 각 픽셀이 모두 "특성"이기 때문에 784개의 특성을 사용하여 z 값을 구하는 것이다.
이 경우에는 바지를 나타내는 z를 계산하는 방정식의 가중치와 절편이 티셔츠를 나타내는 z를 계산하는 방정식의 가중치와 절편이 다르다.
이를 그림으로 나타내면 아래와 같다.
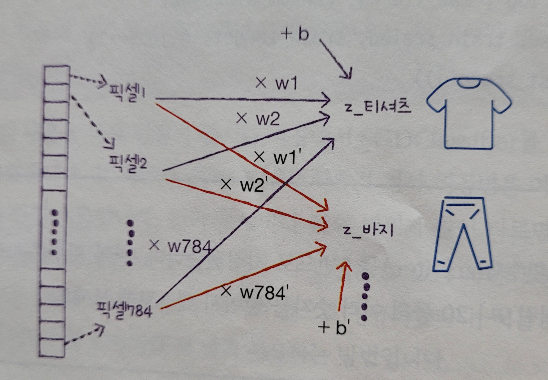
비록 교차 검증의 점수는 만족스럽지 않지만, 확률적 경사 하강법을 사용하는 로지스틱 회귀는 가장 기본적이 "인공 신경망" 모델과 같다.
즉, 위 패션 아이템 분류 문제를 인공 신경망으로 표현하면
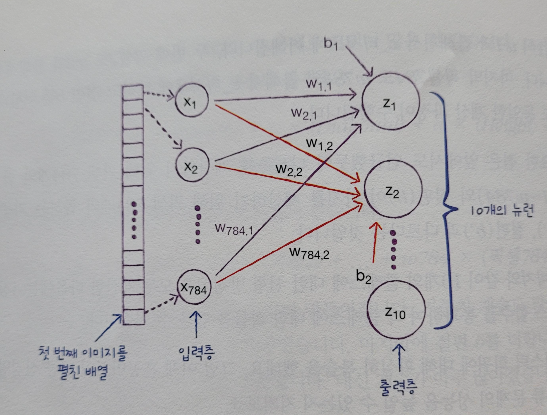
이와 같이 로지스틱 회귀 모델과 거의 유사하다.
예측하는 결과 클래스인 z를 만드는 층을 출력층, 가중치를 곱하는 각 특성을 가진 층을 입력층이라고 하며 z 값을 계산하는 단위를 뉴런 혹은 유닛이라고 한다.
인공 신경망은 기존의 머신러닝 알고리즘이 잘 해결하지 못했던 문제에서 높은 성능을 발휘하는 새로운 종류의 머신러닝 알고리즘이다.
텐서플로(tensorflow)는 이러한 딥러닝 알고리즘을 편리하게 사용할 수 있도록 구글에서 공개한 딥러닝 라이브러리이며, 케라스(Keras)는 이 텐서플로의 고수준 API 이다.
딥러닝 라이브러리는 기본적으로 CPU가 아닌 GPU로 병렬 계산을 수행한다. 하지만 케라스는 직접 GPU 연산을 수행하지 않고 GPU연산을 수행하는 다른 라이브러리를 백엔드로 사용하는데, 이 백엔드 라이브러리 중 하나가 텐서플로이다.
즉, 텐서플로와 케라스는 거의 동의어라고 생각하면 편하다.
이제 진짜로 케라스를 사용하여 위 패션 아이템을 분류하는 인공 신경망을 만들어보자.
우선, 아래와 같이 훈련, 테스트 데이터를 동일하게 준비하고 스케일링한다.
from tensorflow import keras
from sklearn.model_selection import train_test_split
# 훈련 데이터와 테스트 데이터를 나누자.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
머신러닝과 달리 딥러닝은 교차 검증을 사용하게 되면 훈련 시간이 너무 오래 걸리기 때문에 따로 교차검증을 하지 않고 훈련 세트에서 20%를 떼어 검증 세트로 사용한다.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42
)
이제 위 인공 신경망 그림의 오른쪽에 놓인 층을 만들어야 한다. 즉, 10개의 패션 아이템을 분류하기 위한 10개의 뉴런으로 구성된 층을 만든다.
케라스의 Layers 패키지 안에는 다양한 층이 준비가 되어 있다.
이 중 가장 기본이 되는 층은 밀집층인데, 밀집층은 왼쪽에 있는 각 특성(784개)과 오른쪽에 있는 10개의 뉴런이 모두 연결되어 있는 선이 존재하는 층이다.
이런 층을 양쪽의 뉴런이 모두 연결하고 있는 특성 때문에 완전 연결층이라고 부른다.
케라스의 Dense 클래스를 이용하여 이러한 밀집층을 만들어 낼 수 있다.
# Dense(뉴런 개수, activation(출력에 적용할 함수), input_shape(입력의 크기))
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784, ))10개의 뉴런에서 출련되는 값을 확률로 바꾸기 위해 소프트맥스 함수를 사용한다.
소프트맥스 함수와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수를 활성화 함수라고 부르는데, 이러한 활성화 함수의 종류는 굉장히 다양하다.
간단하게 Dense 함수를 사용하는 것으로 신경망 층을 만들었다.
이제 이 밀집층을 가진 신경망 모델을 만들어야 한다.
아래와 같이 케라스의 Sequetial 클래스를 사용한다.
model = keras.Sequential(dense)
케라스 모델은 훈련을 하기 전에 설정하는 단계가 존재한다. 이 설정은 필수로 손실 함수의 종류를 지정해줘야 하며, 아래 코드에서는 훈련 과정에서 계산하고 싶은 측정값(metrics) 또한 지정했다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')categorical_crossentropy 함수를 손실함수로 지정했는데, 이는 확률적 경사 하강법을 배우며 잠깐 다뤘던 크로스 엔트로피의 다중 분류 버전이며, 여기에서 복습할 수 있다.
예를 들면, 티셔츠 샘플의 경우에는 티셔츠 뉴런에 해당하는 확률만 남겨놔야 확실하게 분류가 가능하다.
그렇기 때문에 티셔츠 샘플 뉴런의 활성화 출력에만 1을 곱하고 나머지 활성화 함수 출력에는 0을 곱한다. (원-핫 인코딩)
따라서 다중 분류에서 크로스 엔트로피 손실함수를 사용하기 위해서는 0, 1, 2와 같이 정수로 된 타깃 값을 원-핫 인코딩을 통해 1과 0 뿐인 데이터로 변경해야 한다.
타깃 데이터를 원-한 인코딩한 상태라면 loss='categorical_crossentropy' 으로 지정한 뒤에 진행하면 되지만,
아래와 같이 가지고 있는 패션 데이터는 각 레이블을 정수로 표현한 타깃 데이터를 가지고 있다.
print(train_target[:10])
# [7 3 5 8 6 9 3 3 9 9]
위에서 사용한 loss='sparse_categorical_crossentropy' 가 바로 정수로 된 타깃값을 사용하여 크로스 엔트로피 손실을 계산하는 함수이다.
이제 fit() 함수로 훈련시켜보자.
model.fit(train_scaled, train_target, epochs=5)
# Epoch 1/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.6076 - accuracy: 0.7929
# Epoch 2/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4751 - accuracy: 0.8384
# Epoch 3/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4501 - accuracy: 0.8468
# Epoch 4/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4375 - accuracy: 0.8532
# Epoch 5/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4285 - accuracy: 0.8546케라스는 에포크마다 걸린 시간과 손실, 정확도를 출력해준다! (매우 친ㅡ절)
에포크 5에서 확실히 확률적 경사 하강법을 사용한 로지스틱 회귀 모델보다 성능이 좋아졌다.
이제 evaluate() 함수를 통해 검증 세트에서의 모델 성능을 확인해보면,
model.evaluate(val_scaled, val_target)
# 375/375 [==============================] - 1s 1ms/step - loss: 0.4425 - accuracy: 0.8507훈련 데이터와 비슷한 성능을 보이고 있다.
인공 신경망의 아주 기초적인 구조를 다루면서 케라스를 사용한 간단한 예제를 풀어봤는데, 머신러닝 공부는 이제 시작인 거 같다는 생각이 든다.
앞으로 더 열심히 공부해야겠다.
끝!
'[Python] > Machine learning' 카테고리의 다른 글
| [ML] Deep Learning 3: 신경망 모델 훈련과 최상의 신경망 모델 얻기 (0) | 2023.03.06 |
|---|---|
| [ML] Deep Learning 2: 심층 신경망 (0) | 2023.03.06 |
| [ML] 비지도 학습 3: 주성분 분석 (0) | 2023.03.02 |
| [ML] 비지도 학습 2: k-평균 알고리즘 (0) | 2023.03.01 |
| [ML] 비지도 학습 1: 군집 알고리즘 (0) | 2023.02.28 |




- 인천 구월동 맛집
- redux-thunk
- react
- redux
- AsyncStorage
- Async
- javascript
- 이탈리안 레스토랑
- 정보보안기사 #실기 #정리
- 파니노구스토
- 맛집
- react-native
- Promise
- 인천 구월동 이탈리안 맛집
- await
- Total
- Today
- Yesterday