
티스토리 뷰
지난번 포스팅에서 인공 신경망에 대한 기초적인 지식과 케라스를 사용하여 직접 이를 제작해봤다.
인공 신경망은 하나의 층이 아닌 여러 개의 층을 가질 수 있는데, 층을 더 추가하여 데이터 셋을 더 정확하게 분류하는 심층 신경망을 만들 수 있다.
입력층과 출력층 사이에서 입력 받은 데이터를 가중치와 절편에 따라 중간에서 연산한 뒤, 설정되어 있는 활성화 함수로 출력하여 내보내는 층을 은닉층이라고 하는데, 출력층의 경우에는 활성화 함수로 적용할 수 있는 함수의 종류가 시그모이드(이진), 소프트 맥스(다중)으로 제한되어 있지만, 은닉층의 활성화 함수는 그 종류가 비교적 자유롭다.
대표적인 은닉층의 활성화 함수로 렐루(ReLU) 함수를 사용하는데, 이는 밑에서 다룰 것이다.
(활성화 함수는 분류 문제를 풀기 위해 적용하는 함수임을 기억하자. 회귀 문제는 활성화 함수가 필요 없다.)
심층 신경망의 구조는 아래와 같다.

그럼 예제와 함께 심층 신경망을 구성해보자.
우선, 마찬가지로 패션 아이템 데이터를 로드하고 훈련, 검증, 테스트 세트로 나눈다.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42
)
그 다음에 시그모이드 함수를 사용하는 은닉층과 소프트 맥스를 사용하는 출력층을 Keras의 Dense 클래스를 사용하여 만들어주자.
# 첫번째 신경망 층(은닉층), 은닉층의 뉴런은 반드시 출력층의 뉴런 보다는 많아야 한다.
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
# 두번째 신경망 층
dense2 = keras.layers.Dense(10, activation='softmax')
이제 인공 신경망을 만들 Sequential 클래스에 은닉층과 출력층을 리스트 형태로 넣어 심층 신경망을 만들 수 있다.
# 2개의 층으로 구성된 인공 신경망 생성
model = keras.Sequential([dense1, dense2])이때, 출력층은 반드시 맨 뒤에 나열되어야 한다.
인공 신경망의 강력한 성능은 위와 같이 층을 추가하면서 입력 데이터에 대하여 연속적인 학습을 진행할 수 있다는 점이다.
Keras는 모델의 각 층에 대한 다양한 정보를 제공하는 summary() 함수를 제공한다.
# 층에 대한 유용한 정보를 얻을 수 있는 summary() 함수
model.summary()
# Model: "sequential"
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# dense(Dense)(None, 100)
# 78500
#
# dense_1(Dense)(None, 10)
# 1010
#
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# Total
# params: 79, 510
# Trainable
# params: 79, 510
# Non - trainable
# params: 0각 층의 출력 크기를 보면 (None, 100), (None, 10) 이런 형태로 되어 있는데, 첫번쨰 차원은 샘플의 개수를 나타낸다.
샘플의 개수가 아직 정의되어 있지 않기 때문에 None인데, 그 이유는 케라스 모델의 fit() 메서드에 훈련 데이터를 주입하면 이 데이터를 한번에 모두 사용하지 않고 잘게 나누어 여러 번에 걸쳐 경사 하강법 단계를 수행한다.
이때 배치에 크기에 따라 배치 샘플을 꺼내어 학습하는 미니 배치 경사 하강법을 사용하는데, 샘플 개수를 고정하지 않고 어떤 배치 크기에도 유연하게 대응할 수 있도록 None으로 설정한 것이다.
두번째 차원은 딱 보면 알 수 있듯, 각 층의 뉴런 개수이며 Param은 각 뉴런이 연결된 선으로 생각하면 된다. 각 선을 가중치라고 생각하고, 가중치 + 각 절편(뉴런의 개수)인 값이 바로 param이다.
위 코드처럼 Dense 객체를 먼저 선언한 뒤에 신경망에 넣어줘도 되지만, 아래와 같이 Sequential 객체를 생성하면서 선언해주거나, Sequential 객체가 가지고 있는 add()메서드를 사용해도 된다.
◎ Sequential 생성자에서 직접 생성
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
model.summary()
# Model: "패션 MNIST 모델"
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# hidden(Dense)(None, 100)
# 78500
#
# output(Dense)(None, 10)
# 1010
#
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# Total
# params: 79, 510
# Trainable
# params: 79, 510
# Non - trainable
# params: 0
◎ add()를 사용
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# dense(Dense)(None, 100)
# 78500
#
# output(Dense)(None, 10)
# 1010
#
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# Total
# params: 79, 510
# Trainable
# params: 79, 510
# Non - trainable
# params: 0이제, compile() 메서드로 설정을 해주고, 5번의 에포크 횟수로 훈련을 시켜보자.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
# Epoch 1/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.5637 - accuracy: 0.8080
# Epoch 2/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4113 - accuracy: 0.8523
# Epoch 3/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3757 - accuracy: 0.8637
# Epoch 4/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3533 - accuracy: 0.8716
# Epoch 5/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3368 - accuracy: 0.8779
확실히 층을 추가하기 전 보다 성능이 향상되었다.
렐루(ReLU) 함수
렐루 함수는 인공 신경망에서 가장 많이 사용되는 활성화 함수 중 하나로, 입력값이 양수인 경우 입력값을 그대로 출력하고, 음수인 경우 0을 출력하는 간단한 함수이다.
수식과 그래프는 다음과 같다.
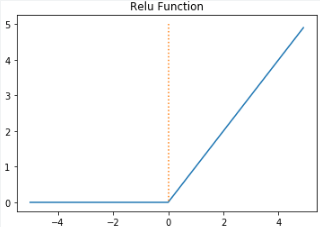
이 함수는 비선형 함수이며, 계산이 간단하고 빠르기 때문에 대부분의 인공신경망에서 많이 사용된다.
입력값이 양수인 부분은 출력값이 선형적으로 변화하며, 음수인 경우는 출력값이 0으로 수렴하는 특징 때문에 주로 은닉층에 사용된다.
Flatten Layer
렐루 함수를 적용하여 심층 신경망을 만드는 코드를 작성하면서, Keras에서 제공하는 편리한 Layer 하나를 더 살펴보려고 한다.
위에서 예제를 위한 데이터를 준비하며 넘파이 배열의 reshape를 활용하여 28x28 크기인 이미지 데이터를 1차원 배열로 펼쳤다.
이렇게 직접 전처리를 해도 되지만, Keras에서는 이를 위한 별도의 층을 제공한다.
Flatten 클래스는 배치 차원은 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할을 한다. 입력에 곱해지는 가중치나 절편이 없는, 인공 신경망의 성능에 딱히 기여하는 바가 없지만 Flatten 클래스를 층처럼 입력층과 은닉층 사이에 추가하기 때문에 이를 층이라고 부른다.
이제 reshape 하는 코드를 한 줄 제거하고, 은닉층의 함수를 ReLU 함수로 변경하여 성능을 확인해보자.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42
)
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
# flatten(Flatten)(None, 784)
# 0
#
# dense(Dense)(None, 100)
# 78500
#
# output(Dense)(None, 10)
# 1010
#
# == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
# Epoch 1/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.5292 - accuracy: 0.8135
# Epoch 2/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3913 - accuracy: 0.8608
# Epoch 3/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3545 - accuracy: 0.8718
# Epoch 4/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3312 - accuracy: 0.8802
# Epoch 5/5
# 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3164 - accuracy: 0.8876시그모이드 함수를 사용했을 때보다 성능이 조금 향상된 걸 확인할 수 있다.
옵티마이저
이전에 하이퍼 파라미터에 대하여 다뤄본 적이 있다. 신경망에는 특히 지정해야 하는 하이퍼 파라미터가 많은데, 예를 들어 뉴런의 개수, 층의 종류, 활성화 함수, 미니 배치의 개수, 에포크 등 굉장히 많다.
compile() 메서드에서는 Keras의 기본 경사 하강법 알고리즘인 RMSprop를 사용하는데, Keras는 다양한 종류의 경사 하강법 알고리즘을 제공한다. 이들을 모두 옵티마이저라고 한다.
즉, 옵티마이저는 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법을 말하는 것이다.
그 종류별로 한번 다뤄보자.
가장 기본적인 옵티마이저는 확률적 경사 하강법인 SGD이다.
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')혹은 optimizer 매개변수에 'sgd'라고 지정하여 자동으로 객체를 생성하게끔 할 수 있다.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
SGD 외에도 다양한 옵티마이저들이 있다. 그 종류와 상세한 설명은 아래 블로그에서 매우 자세하게 설명하고 있으니 참고하자
Ref: https://yngie-c.github.io/deep%20learning/2020/03/19/training_techs
옵티마이저(Optimizer) · Data Science
이번 게시물은 “An overview of gradient descent optimization algorithms” 와 그의 번역인 “Gradient Descent Overview”를 참조하여 작성하였습니다. Optimizer 가중치 초기화(Parameter initialization)를 통해서 시작점을
yngie-c.github.io
옵티마이저의 구체적인 작동 방식이나 최적 파라미터를 찾는 방법은 지금 수준에서 다루기 매우 어려운 거 같다.
지금은 이런게 있구나... 하면서 넘어가자.
끝!
'[Python] > Machine learning' 카테고리의 다른 글
| [ML] Deep Learning 4: 합성곱 신경망(CNN)의 구조 (0) | 2023.03.07 |
|---|---|
| [ML] Deep Learning 3: 신경망 모델 훈련과 최상의 신경망 모델 얻기 (0) | 2023.03.06 |
| [ML] Deep Learning 1: 인공 신경망 (1) | 2023.03.05 |
| [ML] 비지도 학습 3: 주성분 분석 (0) | 2023.03.02 |
| [ML] 비지도 학습 2: k-평균 알고리즘 (0) | 2023.03.01 |




- Promise
- Async
- redux-thunk
- 인천 구월동 이탈리안 맛집
- await
- 인천 구월동 맛집
- 정보보안기사 #실기 #정리
- 맛집
- AsyncStorage
- javascript
- redux
- react-native
- 이탈리안 레스토랑
- react
- 파니노구스토
- Total
- Today
- Yesterday